多层感知机:结构、BatchNorm、Dropout,附 PyTorch 代码
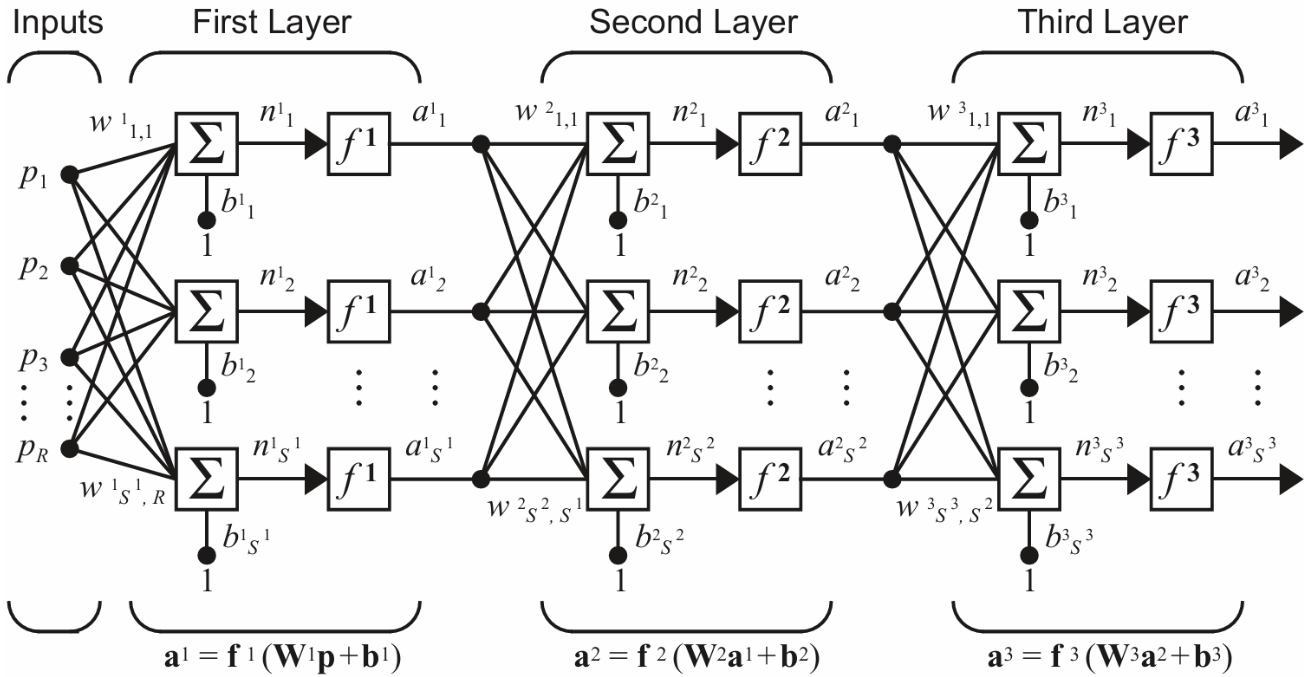
多层感知机(Multi-Layer Perceptron,简称 MLP )是最基础、最常用的前馈神经网络结构之一。它的核心就是把若干个“线性层(全连接)+ 非线性激活函数”堆叠起来,让网络能够拟合复杂的非线性映射。
1. 多层感知机的基本结构
典型的 MLP 由三部分组成:
- 输入层(\(l = 0\)):接收特征 \(\mathbf{p}_i \in \mathbb{R}^{d_0}\),其中 \(d_0\) 为特征维度。即 \(a^{(0)}_i = \mathbf{p}_i\)(单个样本 \(i\))。
- 若干隐藏层(\(l = 1, \cdots, {L-1}\)):
- 一个典型的“层”包含两步:
- 线性变换(可学习层): \[ z^{(l)}_i = W^{(l)}a^{(l-1)}_i + b^{(l)},\quad i = 1, \cdots, B \]
- 非线性激活(不可学习): \[ a^{(l)}_i \leftarrow f^{(l)}(z^{(l)}_i) \]
- 其中:
- \(B\) 为 batch size
- \(z^{(l)}_i,a^{(l)}_i \in \mathbb{R}^{d_l}\)
- \(W^{(l)}\) :第 \(l\) 层的权重矩阵,\(W^{(l)} \in \mathbb{R}^{d_l \times d_{l-1}}\)
- \(b^{(l)}\) :偏置向量,\(b^{(l)} \in \mathbb{R}^{d_l}\)
- \(f^{(l)}(\cdot)\) :非线性激活函数,\(\mathbb{R}^{d_l} \rightarrow \mathbb{R}^{d_l}\)
- 通过多层堆叠\[a^{(l)}_i = f^{(l)}(W^{(l)}a^{(l-1)}_i + b^{(l)})\]实现特征变换,通常包含多个全连接层和非线性激活函数。
- 全连接(fully connected):前一层的每个神经元,都和后一层的每个神经元相连。
- 如果前一层有 \(n\) 个神经元,后一层有 \(m\) 个神经元,那么这一层总共有:\(m \times n\) 个权重 + \(m\) 个偏置,总共 \(m(n+1)\) 个参数。
- 全连接层参数量通常比较大。
- 在 PyTorch 里通常对应
nn.Linear。
- 隐藏层输出维度为 \(d_1, \cdots, d_{L-1}\)
- 一个典型的“层”包含两步:
- 输出层:
- 得到预测 \(\hat y\),通常为一个全连接层。
- 输出维度为 \(d_L\)。
- 分类/回归会用不同输出形式。
如果没有非线性激活(全是线性层),那再多层也等价于“一层线性变换”,表达能力不会变强;非线性是 MLP 能拟合复杂函数的关键。
对一个 batch 输入 \(\mathbf{a}^{(0)} \in \mathbb{R}^{B \times d_0}\),等价于同一个 MLP 被并行地作用在每个样本上。
2. 常见非线性激活函数
\[ \mathrm{ReLU}(x)=\max(0,x) \] 优点:简单、收敛快、缓解梯度消失(相对 Sigmoid/Tanh)。
\[ \mathrm{LeakyReLU}(x)=\max(\alpha x,x),\quad \alpha\in(0,1) \] 特点:负半轴保留小斜率,减少“神经元死亡”。
\[ \sigma(x)=\frac{1}{1+e^{-x}} \] 特点:输出在 \((0,1)\) 区间,常用于二分类输出层;隐藏层使用时更容易梯度消失。
\[ \tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} \] 特点:输出在 \((-1,1)\),比 Sigmoid 零均值,但仍可能梯度消失。
\[ \mathrm{GELU}(x)=x\Phi(x) \] 其中 \(\Phi(x)\) 为标准正态分布的累积分布函数。特点:比 ReLU 更“平滑”。
3. BatchNorm
实现中最常见顺序:
Linear -> BN -> ReLU
BatchNorm(批归一化)一般作用在每个隐藏层的线性输出上 \[ \mathbf{z}^{(l)} = \begin{bmatrix} (z^{(l)}_{1})^\top\\ \vdots\\ (z^{(l)}_{B})^\top \end{bmatrix} = \begin{bmatrix} \big(W^{(l)} a^{(l-1)}_{1}+b^{(l)}\big)^\top\\ \vdots\\ \big(W^{(l)} a^{(l-1)}_{B}+b^{(l)}\big)^\top \end{bmatrix} \in \mathbb{R}^{B\times d_l}. \]
先对每个特征维度 \(j\)(也就是每个神经元通道)在一个 batch 上计算均值和方差: \[ \mu_j^{(l)}=\frac{1}{B}\sum_{i=1}^B z_{i,j}^{(l)},\qquad (\sigma_j^{(l)})^2=\frac{1}{B}\sum_{i=1}^B(z_{i,j}^{(l)}-\mu_j^{(l)})^2 \] 定义标准化: \[ \hat z^{(l)}_{i,j}=\frac{z^{(l)}_{i,j}-\mu_j^{(l)}}{\sqrt{(\sigma_j^{(l)})^2+\varepsilon}}, \] 其中,\(\varepsilon\) 是一个小常数,用于防止除零错误。
再做可学习缩放平移(\(\gamma^{(l)},\beta^{(l)} \in \mathbb{R}^{d_l}\)): \[ \tilde{z}_{i,j}^{(l)} = \gamma_j^{(l)} \hat z^{(l)}_{i,j}+\beta_j^{(l)}, \] 然后再激活: \[ \tilde{a}_i^{(l)} = f^{(l)}(\tilde{z}_i^{(l)}). \]
BatchNorm 的常见作用:
- 稳定训练、加速收敛
- 对不同 batch 的统计量带来一定“噪声”,具有一定正则化效果
BatchNorm 对 batch size 较敏感,batch 太小(甚至为 1)时效果会明显变差;这时常用 LayerNorm / GroupNorm。
4. Dropout
实现中最常见顺序:
Linear -> BN -> ReLU -> Dropout
Dropout 在训练时随机把一部分样本的一部分神经元激活输出置零,避免网络过度依赖少数神经元,从而抑制过拟合。
比如隐藏层激活为: \[ \mathbf{a}^{(l)} = \begin{bmatrix} (a_1^{(l)})^\top\\ \vdots\\ (a_B^{(l)})^\top \end{bmatrix} = \begin{bmatrix} (f(z_1^{(l)}))^\top\\ \vdots\\ (f(z_B^{(l)}))^\top \end{bmatrix} \in\mathbb{R}^{B\times d_l}. \]
Dropout 产生 mask \(m^{(l)}\in \{0,1\}^{B\times d_l}\),然后 \[ h^{(l)}=\frac{m^{(l)}\odot \mathbf{a}^{(l)}}{1-p}. \] 也就是说:被 mask 为 0 的那些元素(某些样本的某些神经元输出)在这一轮前向里直接变成 0。
- \(m\)(mask)是一个随机 0/1 矩阵(或向量),和 \(\mathbf{a}^{(l)}\) 同形状。
- 其中,\(m_{i,j}\sim \mathrm{Bernoulli}(1-p)\): 每个 \(m_{i,j}\) 独立地取值 \[ m_{i,j}=\begin{cases} 1,&\text{概率 }1-p \\ 0,&\text{概率 }p \end{cases} \] 这就是伯努利分布(Bernoulli distribution),只有 \(0/1\) 两种结果的最基本随机分布。
为什么要除以 \(1-p\)?这是 “inverted dropout” 的写法:
- 训练时:把保留下来的激活放大,使得期望不变;
- 推理时:直接关掉 Dropout(不再随机置零,也不需要缩放,直接使用 \(\mathbf{a}^{(l)}\))。
5. PyTorch 三种结构的初始化代码
PyTorch:一个面向深度学习、可运行在 CPU 和 GPU 上的优化张量库。- 不只是写神经网络的库,
- 而是一整套从张量计算、自动求导、网络搭建、优化训练到数据加载的生态。
下面给出 PyTorch 三种结构的初始化代码。
1 | |
1 | |
1 | |
小结:三者区别一句话
- 经典多层感知机(MLP):Linear + 激活,最基础的非线性拟合器
- MLP + BatchNorm:在层间加入归一化,训练更稳定、收敛更快
- MLP + BatchNorm + Dropout:再加随机丢弃,进一步抑制过拟合(但训练噪声更大)
super()的作用:调用父类的方法。- 使用
super().__init__()执行父类nn.Module的初始化方法。
- 使用
每一层隐藏层维度都可以不同,下面给出相应的代码。
1 | |
1 | |
1 | |
nn.Sequential的作用:顺序容器。把若干层按顺序放进去,输入会自动一层一层往后传。- 输入:扁平的层序列,而不是“列表套列表”。
*layers里的*表示 解包。
神经网络的维度:
1 | |
那么:
1 | |
循环时就会依次生成:
1 | |
最后再接:
1 | |
所以整个网络就是:
\[ 1 \to 32 \to 64 \to 16 \to 1 \]
这就明确体现了:
- 第 1 个隐藏层是 32 维
- 第 2 个隐藏层是 64 维
- 第 3 个隐藏层是 16 维
使用示例
1 | |
这表示网络为:
\[ 10 \to 64 \to 128 \to 32 \to 2 \]
如果输入 x 的形状是:
1 | |
那么输出就是:
1 | |
在很多任务里,神经网络的最后一层常常先写成 Linear,然后是否再接激活函数,要看任务类型。
依据:输出空间的数学性质和损失函数的搭配。
例如输出一个实数、多个连续值:
1 | |
通常最后一层直接是 Linear,后面不加激活
因为回归值可能是任意实数。
例如:
1 | |
若输出类别 0/1,常见有两种写法:
写法 A:最后层是 Linear,不手动加 Sigmoid 训练时配合:
1 | |
写法 B:最后层后面手动加 Sigmoid
把输出压到 (0,1),作为概率。
通常最后一层仍然是:
1 | |
输出每个类别的 score,也就是 logits。
训练时一般直接配:
1 | |
这时通常不要手动再加 Softmax 因为 CrossEntropyLoss 内部已经处理了。
如果希望输出满足某种范围,就可能不用 Linear 结尾。
例如:
- 输出必须在
(0,1):可考虑Sigmoid - 输出必须在
(-1,1):可考虑Tanh - 输出必须大于 0:可考虑
Softplus或exp
6. 参数(parameter)与超参数(hyperparameter)
6.1 统计学角度
“超”这里对应英文 hyper-,意思不是“超级厉害”,而是“更高一层”。
hyperparameter 这个词最早在统计学、尤其贝叶斯统计里很常见。
比如:
- 一个分布有参数
- 而这个分布参数本身又来自另一个分布
- 这个更高层分布的参数就叫 hyperparameters
所以“hyper-”本来就带有“上一层、管下一层”的意思。
后来机器学习把这个说法沿用了过来。
- 参数(parameters):模型内部的可学习变量
- 超参数(hyperparameters):决定参数如何被学习、或者决定参数空间长什么样的设置
所以超参数比普通参数“高一层”。
超参数是在训练前或训练过程中人为设定的那些量,它们通常不直接通过标准训练过程自动学出来,而是决定:
- 模型怎么学
- 学多快
- 学多久
- 模型长什么样
常见例子有:
- 学习率
learning rate - batch size
- 训练轮数
epochs - 隐藏层数
- 每层神经元个数
- dropout 比例
- 权重衰减系数
- 优化器类型
这些量不属于网络内部“被拟合”的权重,但会显著影响最终学到的权重。 不能通过与参数训练相同的步骤直接得到,通常需要:
- 人工经验设定
- 网格搜索
- 随机搜索
- 贝叶斯优化
- 验证集调参
6.2 优化角度
从优化角度看,神经网络训练常常像两层问题:
- 内层:固定超参数后,优化模型参数 \(\theta\)(如权重
W、偏置b、BatchNorm 的 \(\gamma,\beta\) 等),使得损失函数 \(L(\theta)\) 最小。即- \(\theta^* = \arg\min_\theta L(\theta;\lambda)\)
- 其中
- \(\theta\) :模型参数,能通过反向传播、梯度下降从数据中自动学出来
- \(\lambda\) :超参数
- 内层优化是针对模型参数 \(\theta\) 的优化
- 外层:选择超参数 \(\lambda\)(如学习率、隐藏层维度、Dropout 概率等),使得模型在验证集上表现最好。即:
- \(\lambda^* = \arg\min_\lambda L_{\text{val}}(\theta^*(\lambda))\)
- 其中
- \(L_{\text{val}}\) :验证集上的损失函数
- \(\theta^*(\lambda)\) :内层优化得到的最优参数,依赖于超参数 \(\lambda\)。
- 外层优化是针对超参数 \(\lambda\) 的优化。
- 所以超参数其实是控制参数解的更上层变量,因此用
hyper这个名字。
6.3 超参数并不是绝对不能学
现在有些方法可以自动调整一部分超参数,比如:
- 学习率调度
- 神经架构搜索
- 元学习
- 可学习的温度系数、正则系数
所以“超参数”是说它不属于标准反向传播直接优化的那组模型参数,或者说它处在更外层。